宽客财经
关注微信公众号"宽客财经",定时推送前沿、专业、深度的交易极客和量化投资资讯。
搜索
关注微信公众号"宽客财经",定时推送前沿、专业、深度的交易极客和量化投资资讯。
|
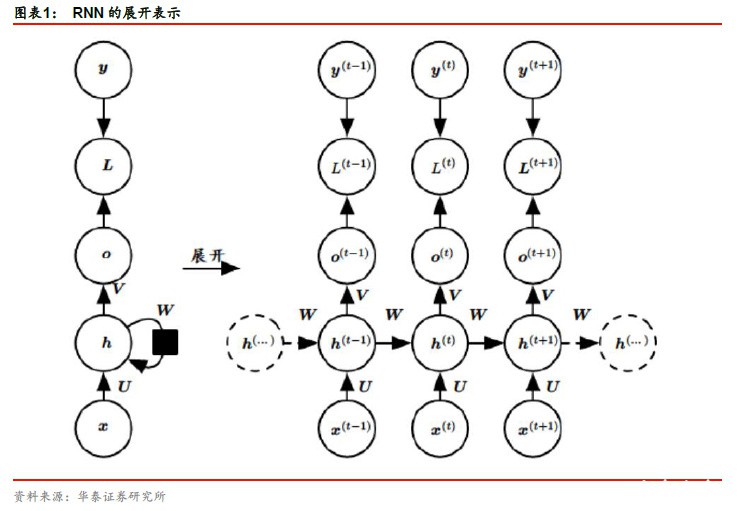
1 什么是RNN RNN,顾名思义,是包含循环的神经网络。它与传统神经网络模型最大不同之处是加入了对时序数据的处理。以股票多因子为例,传统神经网络在某一时间截面的输入因子数据,输出下期超额收益预测;而RNN是将某支股票的长期因子数据作为时间序列,取过去一段时间内的数据作为输入值。资本市场的信息有着一定持久性,使用RNN可以充分把握“历史重演”的机会。 如图表1 左侧所示,RNN读取某个输入x,并输出一个值o,循环可以使得信息从当前步传递到下一步。从表面看,这样的网络结构较难理解,因此将其展开为图表1 右侧。对于从序列索引1 到T 的时间序列数据,如果关注t时刻附近的网络结构,xt代表了在序列索引号t 时刻训练样本的输入,同理xt−1和xt+1代表了在序列索引号t−1 时刻和t+1 时刻训练样本的输入;ht代表在t 时刻模型的隐藏状态,不仅由xt决定,也受到ht−1的影响;ot代表在t 时刻模型的输出,ot只由模型当前的隐藏状态ht决定;yt是t 时刻样本序列的真实值;Lt是t 时刻模型的损失函数,通过ot和yt计算得出;U、V、W 这三个矩阵是模型的参数,它们在整个模型中是共享的。
RNN 模型本质上也是采用BP(Back Propagation)算法进行权值和阈值的调整优化,只是增加了时间序列,叫做BPTT(Back Propagation Through Time)。公式如下:
 其中Ct表示t时刻模型输出与真实值之间的交叉熵。对于上述公式中,如果σ为sigmoid 函数或者 tanh 函数,根据δ的递推式,当时间跨度较大时,δ就会很小,从而使 BP 的梯度很小,产生“梯度消失”。 另外,对于参数Whh:由于RNN 中Whh在每个时刻都是指的相同参数,所以δ中会出现Whh的累乘。而多次累乘后,数值的分布有明显的趋势:要么趋近于0,要么趋近于绝对值很大的值。而这两种情况,就很可能会分别造成“梯度消失”和“梯度爆炸”。 2 什么是LSTM 传统RNN 模型容易产生梯度消失的问题,难以处理长序列的数据。因此Hochreater 和Schmidhuber 在1997 年提出了长短期记忆网络LSTM,通过用精心设计的隐藏层神经元缓解了传统RNN的梯度消失问题。 3 LSTM V.S. RNN 在RNN 模型中,在每个序列索引位置都有一个隐藏状态ht,如果我们略去每层都有的ot,yt和 Lt,那么模型可以简化为如图表4 的形式,通过线条指示的路径可以清晰地看出隐藏状态ht由ht−1和xt共同决定。ht将一方面用于计算当前层模型的损失,另一方面用于计算下一层的ht+1。 
LSTM 模型中,每个序列索引位置t时刻被向前传播的,除了和RNN 一样的隐藏状态ht,还多了另一个隐藏状态,如图表6中的标黑横线。这个隐藏状态被我们称为细胞状态Ct(Cell State),细胞也就是LSTM的一个单元。Ct在LSTM 中实质上起到了RNN 中隐层状态ht的作用。 
4 LSTM的单元结构 除了细胞状态,LSTM的单元还有其他许多结构,这些结构一般称之为门控结构(Gate)。LSTM 模型在每个序列索引位置t的门控结构一般包括输入门(Input Gate), 输出门(Output Gate), 忘记门(Forget Gate):这三个 Gate 本质上就是权值,形象地说,类似电路中用于控制电流的开关。当值为1,表示开关闭合,流量无损耗流过;当值为0,表示开关打开,完全阻塞流量;当值介于(0,1),则表示流量通过的程度。而这种[0,1]的取值,其实就是通过激活函数实现的。  门.  由上述的结构分析可知,LSTM 只能避免RNN 的“梯度消失”。“梯度膨胀”虽然不是个严重的问题,但它会导致参数会被修改的非常远离当前值,使得大量已完成的优化工作成为无用功。当然,“梯度膨胀”可以采用梯度裁剪(gradient clipping)来优化(如果梯度的范数大于某个给定值,将梯度同比收缩)。 5 LSTM小结 总结而言,LSTM内部主要有三个阶段:
|