|
在计量经济学领域中,我们主要研究三种数据,即横截面数据、面板数据和时间序列数据。其中横截面数据研究在一个给定的时间点上,不同观测样本的状态,例如:2016年12月16日全国各个城市天气质量AQI指数。面板数据指的是某些给定的样本在给定的时间跨度内的观测值。例如:2016年全国各个城市每日的天气质量指数。而时间序列研究一个个体在一段时间跨度内的变化。其特点为,每个观测值前后相关性很强,基本很难满足简单最小二乘法中随机抽样的假设。故时间序列数据有自己独特的一套研究方法,常用模型包括均值模型,波动率模型,非平稳模型等。 Python中的statsmodels工具包中的tsa模块提供了时间序列的函数,包括ARMA,VAR等模型,方便我们使用。 在这部分中,我主要介绍移动平均和平稳性两部分内容。 1. 移动平均(Moving average) 移动平均是用来刻画一个时间序列在最近一段时间内的走势的指标,其波动比原序列要小,平滑期数越长移动平均值越平缓。移动平均广泛的应用在各种股票的技术分析指标中(即均线),长短期均线结合使用可作为资产走势的判断依据,例如MACD,DMA,CCI等。均线是对趋势的确认,有滞后性。包括有简单移动平均,指数移动平均等。 a) 简单移动平均(Simple moving average): M期简单移动平均计算方法为
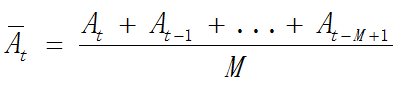
其中A为原始序列, A-bar为平滑后的数据。 A-bar为平滑后的数据。 此处以沪深300为例,利用matplotlib画出今年300指数的价格和十五日均线。
- mport matplotlib.pyplot as plt
- from pandas import DataFrame
- def macd(priceSer,n):
- return priceSer[-n:].mean()
- df=get_price('000300.SH',start_date='2016-01-01',end_date='2016-12-15',fields=['close'])
- MA=[]
- for i in range(df.__len__()):
- MA.append(macd(df['close'][:i],15))
- df['MA']=MA
- plt.plot(df)
- plt.show()
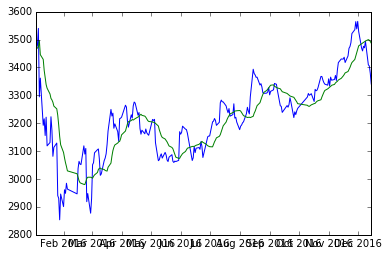
可以看到,均线反映了滞后的走势信息。 b) 加权移动平均(Weighted moving average): 简单移动平均相当于给滞后期内的数据同等权重,而加权移动平均则对滞后期内数据赋予不同的权重。往往会给较短滞后期的数据赋予更高的权重,因为事件发生过去的时间越近,对现在的情况的影响越大。加权移动平均的特例是指数移动平均(Exponential moving average。可用递推表达式表示: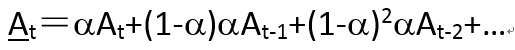 其等价于: 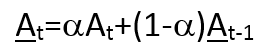
在选择移动平均滞后期和指数移动平均的系数a的时候,应根据原始数据的特征判断。若原始数据波动较大,则应选择较长的滞后期,和较小的a;若原始数据较平稳,则应选择较短的滞后期和较大的a。这样可以获得容易观察到明显趋势的均线。 2. 平稳性(Stationary) 平稳性,简单来讲就是统计性质不随时间改变的性质。它是时间序列分析中的一条重要假设。我们平常讨论的平稳条件,指的是宽平稳条件,即随机过程Xt的均值、方差均不随时间t改变,且Xt与Xs的协方差只和t-s有关系。 为什么时间序列分析要求输入序列平稳呢?大数定律和中心极限定理是很多统计推断的依据。而这两个定理都要求样本是随机抽样的。在时间序列中,这个要求就等价于上述平稳序列的条件。同时,非平稳的时间序列会导致伪回归的问题。所以说,平稳性是时间序列分析的前提。 我们仍然以沪深300指数今年的价格线为例。首先绘制价格线的折线图,可以明显发现价格带有趋势性,是非平稳的序列,不符合时间序列的基本假设。
| 



















